While a single parallel algorithm implemented directly in hardware may execute faster than the same algorithm being run sequentially on a von Neumann machine, the difference may be quite small. Also, the overhead associated with general purpose reconfigurable hardware such as the cell matrix may actually be greater than the hardware associated with a general purpose processor executing a software version of the same algorithm.
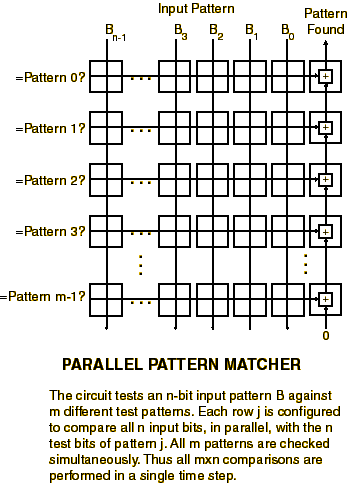
There is, however, a tremendous speed advantage of the cell matrix when parallel algorithms are executed. This is because, unlike traditional von Neumann machines (which contain a single CPU), the cell matrix can be configured with many parallel circuits to implement algorithms in parallel. For example, if we wish to check an input string for one of 100 different substrings, we could devise a circuit which checks for all 100 simultaneously. Such a scheme is shown to the right. This circuit compares the input against all 100 test strings without any looping. More generally, we can build a circuit which searches against "k" strings in a fixed amount of time (propagation delays aside), i.e., its execution time is O(1).
On a von Neumann machine, these substrings would need to be checked sequentially, meaning 100 separate checks. To check k strings requires k steps, i.e., its execution time is O(k). The larger the search space, the more efficient the cell matrix is vs. a von Neumann solution (and the bigger the cell matrix circuit is).
Moreover, because of the cell matrix's self-configurability, it can also be configured to perform parallel configuration of other circuits. Thus, a parallel circuit can be efficiently modified in parallel to change its behavior. This is a key feature for efficiently constructing large parallel circuits.
Because configuration control is distributed throughout the matrix, the cell matrix avoids configuration bottlenecks which would result from relying on a centralized controller.
other features . core